Introducción a las bases de datos
Introducción
Una base de datos (BD) es una colección de datos estructurados que contiene información relevante para una empresa, entidad, etc.
Un sistema de gestión de bases de datos (SGBD o DBMS) es el conjunto formado por los programas que nos permiten tratar los datos. Su objetivo es proporcionar a los usuarios una forma práctica y eficiente de almacenar y recuperar los datos.
Los SGBD suelen utilizarse para gestionar grandes cantidades de datos, encargándose de salvaguardar uno de los bienes más importantes de las empresas: sus datos.
Aplicaciones de los sistemas de gestión de base de datos
Los escenarios más habituales de los SGBD son:
Banca: clientes, cuentas, préstamos, transacciones.
Compañías aéreas: reservas y horarios. Pioneras en BB.DD. distribuidas.
Docencia: estudiantes, matrículas, cursos.
Transacciones de tarjetas de crédito: compras, extractos.
Telecomunicaciones: llamadas realizadas, facturas, saldos prepago.
Finanzas: Bonos, acciones, compraventa en línea.
Ventas: clientes, productos, compras.
Comercio en línea (E-commerce): datos de ventas, seguimiento de pedidos, listas de recomendaciones, evaluaciones de productos.
Logística: proveedores, inventarios, pedidos.
Recursos humanos: empleados, salarios, impuestos, nóminas.
Hasta que no aparecen los SGBD, la información se almacenaba en el sistema de archivos del propio sistema operativo, lo cual tenía aparejado un conjunto de problemas:
Redundancia e inconsistencia: como la información estaba almacenada en distintos ficheros se producían:
Redundancia de los datos con aumentos en los costes de almacenamiento.
Inconsistencia de los datos cuando distintas copias del mismo dato tienen valores diferentes.
Dificultad de acceso a datos: como los datos estaban almacenados en ficheros, era necesario la implementación de aplicaciones particulares para extraer la información concreta.
Aislamiento de los datos: los datos estaban dispersos en varios ficheros y en diferentes formatos, dificultando que se pudieran hacer nuevos programas para recuperar los datos correspondientes.
Problemas de integridad: en los sistemas de archivos, las restricciones se controlaban por código, así que cuando era necesario añadir nuevas restricciones había que replicar las antiguas en las nuevas aplicaciones y las nuevas en las antiguas, dificultando el mantenimiento de la integridad.
Problemas de atomicidad: en los sistemas puede haber fallos, siendo necesario asegurar que cuando el sistema se restablezca los datos sean consistentes. Ejemplo: Si durante una transferencia de una "cuenta A" a una "cuenta B" se produce un fallo, es posible que se reste el saldo de la "cuenta A" sin llegar a ingresarse en la "cuenta B".
Debemos garantizar que las operaciones se realizan completamente o no se realiza nada.
Anomalías en el acceso concurrente: Al acceder de forma simultánea a los datos pueden producirse problemas de inconsistencia, pues al estar una aplicación trabajando con un dato, si otra intenta acceder a este cuando aun no es un dato fijo, puede propagarse el dato inconsistente al resto de datos.
Esto sucede cuando los programas (sin SGBD) no se han coordinado previamente.
Problemas de seguridad: esto ocurre cuando todos los usuarios pueden ver y manipular todos los datos, sin distinguir entre diferentes perfiles.
Estos problemas favorecieron el desarrollo de SGBD y en la aparición de las propiedades ACID de las BD, fundamentales para garantizar la integridad de los datos.
Propiedades ACID
Atomicidad: Se realizan todas las operaciones o ninguna.
Consistencia: La ejecución de una operación debe garantizar la integridad de los datos.
Aislamiento (Isolation): Asegura que si hay varias operaciones ejecutándose sobre el mismo dato, el resultado será equivalente a la realización de dichas operaciones secuencialmente.
Durabilidad: Si una operación finaliza con éxito, los efectos permanecen aunque se caiga el sistema.
Visión de los datos
El SGBD debe presentar una visión abstracta de los datos, ocultando a los usuarios detalles de bajo nivel. Para ello, se establecen diferentes niveles de abstracción, a los que acceden usuarios de diferentes perfiles en función de su papel en el SGBD:
Nivel físico: describe cómo se almacenan los datos.
Nivel lógico: se centra en qué datos se deben almacenar y cómo se relacionan entre sí.
Nivel de vistas: permite mostrar parte de la BD a los usuarios.
Bases de datos relacionales
Las bases de datos relacionales se caracterizan porque almacenan los datos a partir de tablas.
Incluyen lenguajes para manipular dichos datos, que normalmente se clasifican en dos tipos:
Lenguaje de manipulación de datos (DML, del inglés Data Manipulation Language).
Lenguaje de definición de datos (DDL, del inglés Data Definition Language).
Tablas
Una tabla es una estructura compuesta por filas y columnas, cada una de ellas con un nombre único en la BD.
Cada tabla es un conjunto de entidades donde:
Las filas son las entidades.
Las columnas son los atributos.
Ejemplo: en una entidad bancaria tendremos una tabla para los clientes, de los que almacenaremos su código, nombre, dirección y localidad.
Lenguaje de manipulación de datos (DML)
SQL es un lenguaje declarativo, por lo que requiere que el usuario especifique qué datos necesita sin indicar cómo se han obtenido esos datos.
Se utilizan como entrada una o varias tablas, devolviendo siempre una sola.
Ejemplo: consulta SQL en la que se recupera el nombre (SELECT) de todos los clientes (FROM) que tienen la característica (WHERE) de residir en Jaén.
xxxxxxxxxx31SELECT cliente.nombre_cliente2FROM cliente3WHERE cliente.ciudad_cliente = ‘Jaén’
Esta consulta devolverá una tabla con un único atributo, nombre_cliente, y dos registros, Mariano y Yolanda.
Dentro de las consultas se puede utilizar información de más de una tabla.
xxxxxxxxxx31SELECT cuenta.numero_cuenta, cuenta.saldo2FROM impositor, cuenta3WHERE impositor.id_cliente = ‘29’ and impositor.numero_cuenta=cuenta.numero_cuenta
Si esta consulta la ejecutamos sobre nuestro ejemplo, nos devolvería una tabla con dos atributos (numero_cuenta y saldo) y dos filas: (C-100, 1999) y (C-055, 7000).
Lenguaje de definición de datos (DDL)
SQL tiene un DDL en el que podemos definir tablas, restricciones de integridad, asertos, etc.
xxxxxxxxxx31create table cuenta (2numeroCuenta char(10),3saldo integer);
Acceso a las bases de datos desde los programas de aplicación
Algunos cálculos no pueden obtenerse mediante ninguna consulta SQL. Para poder realizarlos se debe utilizar un lenguaje anfitrión como Cobol, C, C++ o Java.
Para acceder a la base de datos, las órdenes DML deben ser realizadas a través de un lenguaje anfitrión, lo cual puede hacerse de dos maneras diferentes:
Incorporando una interfaz con programas de aplicación que permita enviar instrucciones de tipo DML y DDL a la base de datos.
Realizando una extensión de la sintaxis del lenguaje anfitrión para que logre incorporar las llamadas DML en el programa desarrollado en el lenguaje anfitrión.
El diseño de base de datos
Cuando se diseña un sistema de base de datos, su finalidad principal es hacer que se pueda gestionar una gran cantidad de información.
Por lo tanto, el diseño de base de datos implica la elaboración o desarrollo del esquema de dichas bases.
Como en cualquier otro software, es necesario familiarizarnos con la empresa para la que estamos diseñando las bases de datos y seguir un proceso de abstracción para conseguir plantear un sistema que resuelva las necesidades del cliente.
Proceso de diseño
El proceso de diseño de la BD tiene el objetivo de conocer los requisitos de los distintos usuarios del sistema.
Primero se recogen lo requisitos y a continuación se traducen esos requisitos en un esquema conceptual de la base de datos, el cual nos ofrecerá una visión general y detallada de la empresa.
Después, el diseñador revisará el esquema para centrarse en describir los datos y sus relaciones.
Existen dos fases de diseño finales para afianzar el diseño preliminar abstracto de datos:
Fase de diseño lógico: transforma el modelo conceptual en modelo de datos del sistema que se va a implementar.
Fase de diseño físico: específica, por ejemplo, la organización de los ficheros y las estructuras de almacenamiento interno.
El modelo entidad-relación
El modelo entidad-relación define los objetos de datos que se procesan en el sistema, los atributos que tienen y las relaciones entre ellos.
Entidad: cualquier elemento del mundo real que es distinguible de otros objetos.
Atributos: características que definen o identifican a una entidad. Todas las entidades tienen un atributo adicional que será su identificador dentro del sistema, son llamados atributos identificativos.
Relaciones: conjunto de relaciones de la misma naturaleza.
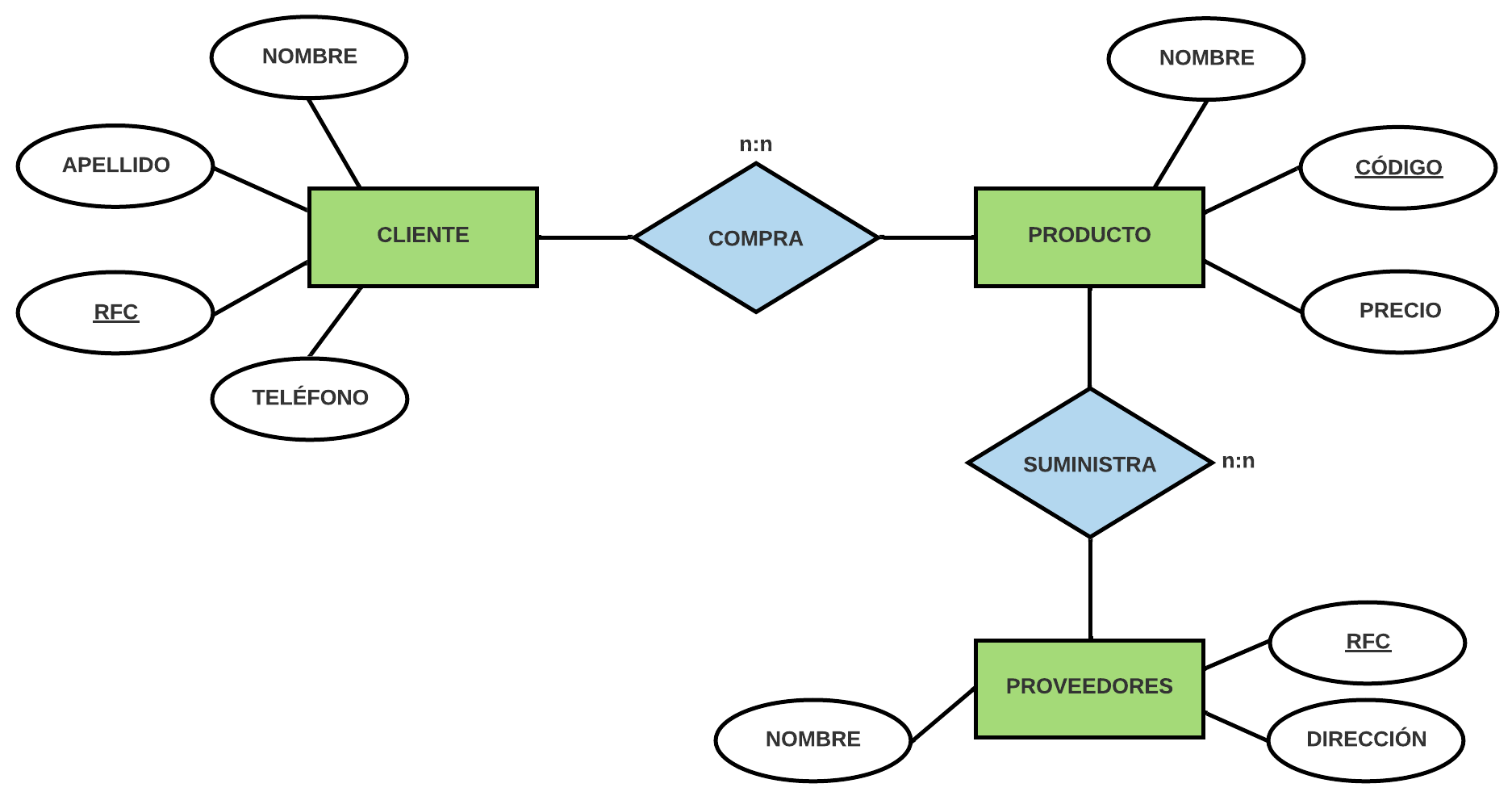
La estructura lógica de la BD en el modelo entidad-relación se puede expresar gráficamente mediante un diagrama entidad-relación.
Diagrama entidad-relación
Los diagramas entidad-relación sirven para modelar la información desde un punto de vista estático.
Una restricción importante en el modelo entidad-relación es la cardinalidad de las relaciones, que expresa el número de entidades de un conjunto de entidades con el que puede relacionarse una entidad de otro conjunto con el que tenga relación.
Elementos:
Entidades: rectángulos etiquetados con nombre.
Atributos: elipses conectadas a la entidad.
Relaciones: Líneas con un diamante central con la cardinalidad en los extremos.
Normalización
La normalización tiene como fin realizar una organización eficiente de los diferentes datos que están almacenados en la base de datos.
Los principales objetivos de la normalización son:
Supresión de datos redundantes.
Facilidad en la representación de la información.
Bases de datos basadas en objetos y semiestructuradas
Algunas aplicaciones no pueden manejarse adecuadamente por medio del modelo relacional, por lo que surgen otros para tratar dichos dominios de aplicación.
El modelo de datos orientado a objetos se basa en el paradigma de programación orientado a objetos, incluyendo algunos de sus conceptos más representativos como herencia o encapsulación.
El modelo de datos relacional orientado a objetos incluye datos estructurados y colecciones.
los modelos de datos semiestructurados permiten que los datos del mismo tipo estén definidos por conjuntos de datos diferentes.
Almacenamiento de datos y consultas
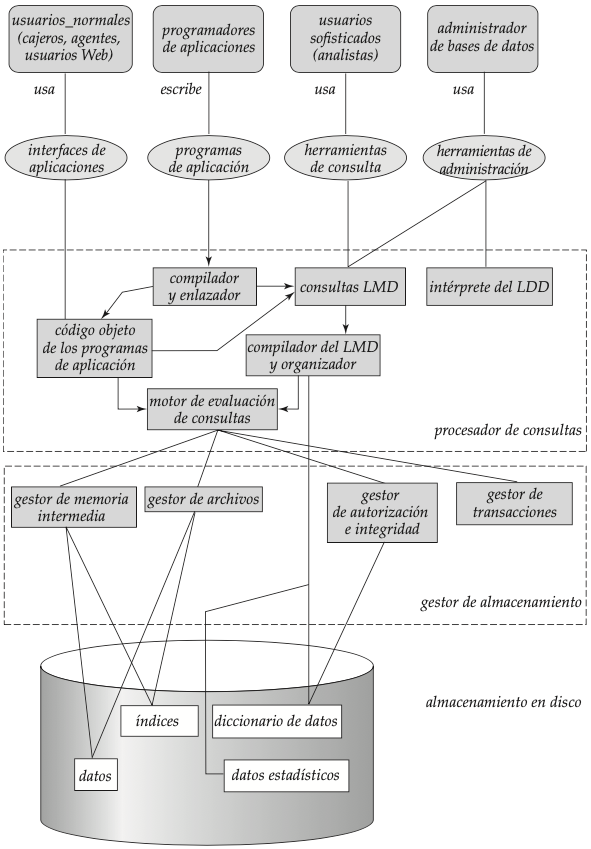
Los SGBD tienen diferentes módulos que se encargan de diferentes funcionalidades:
Gestor de almacenamiento: se encarga de optimizar el movimiento de datos entre memoria principal y disco para conseguir una velocidad de respuesta óptima.
Se encarga de traducir las instrucciones DML a comandos del sistema de archivos.
Gestión de transacciones
Una transacción es un conjunto de operaciones que realiza una única función lógica y constituye la unidad de atomicidad y consistencia.
Es responsabilidad del programador delimitar las transacciones correctamente para que el sistema pueda mantener consistencia de la BD. Sin embargo, garantizar la atomicidad y durabilidad es responsabilidad del sistema.
De esta forma, si el sistema falla cuando una transacción se está ejecutando, esta no tendrá ningún efecto sobre el sistema. Para ello, se realizará un proceso de recuperación de fallos que restaurará la base de datos a un estado consistente anterior.
Por su parte, el gestor de control de concurrencia controla que la interacción entre transacciones concurrentes sea correcta y el resultado sea consistente.
Minería y análisis de datos
La minería de datos es el análisis semiautomático de grandes bases de datos para descubrir patrones útiles con el fin de construir reglas que permitan predecir comportamientos con cierto grado de confianza.
Los datos textuales se caracterizan por no tener una estructura, por lo que su tratamiento es, generalmente, más complejo. Los sistemas que trabajan con este tipo de datos lo hacen a partir de lo que se conoce como recuperación de información y se basan en el reconocimiento de palabras clave, en la asignación de relevancia a los documentos, en el análisis, en la clasificación y en la indexación de los documentos.
Arquitectura de las bases de datos
La arquitectura de una BD está fuertemente influenciada por el sistema informático subyacente. Puede estar centralizada, ser cliente-servidor, estar sobre máquinas paralelas o estar distribuida geográficamente. No obstante, cualquier arquitectura de base de datos debe tener tres características:
Emplear un nivel de independencia en los diferentes programas y los datos.
Crear vistas para los usuarios.
Utilizar un registro para almacenar el esquema de nuestra BD.
Arquitectura de tres niveles
La arquitectura de tres niveles fue planteada por ANSI-SPARC (American National Standard Institute - Standards Planning and Requirements Committee) y está compuesta por tres niveles que satisface las tres características que debe tener cualquier arquitectura de base de datos.
Nivel interno: describe la estructura física de almacenamiento.
Nivel conceptual: Describe la estructura de los datos.
Nivel externo: Describe la visión que los usuarios tienen de los datos.
La arquitectura de tres niveles es útil para explicar el concepto de independencia de datos, que tiene la capacidad para cambiar el esquema en un nivel del sistema sin tener que modificar el esquema del nivel inmediatamente superior.